Pengelompokan Dalam Data Mining

a. Deskripsi
Terkadang peneliti dan analisis secara sederhana
ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang
terdapat dalam data. Deskripsi dari pola kecenderungan sering memberikan
kemungkinan penjelasan untuk suatu pola atau kecenderungan.
b. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali
variabel target estimasi lebih ke arah numerik dari padake arah kategori. Model
dibangun menggunakan baris data (record) lengkap yang
menyediakan nilai dari variabel target sebagai nilai prediksi.Selanjutnya, pada
peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan
nilai variabel prediksi.
Baca Juga :
c. Prediksi
Prediksi hampir sama dengan klasifikasi dan
estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada di masa
mendatang. Beberapa metode dan teknik yang digunakan dalam klasifikasi dan
estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
d. Klasifikasi
Dalam klasifikasi, terdapat target variabel
kategori. Sebagai contoh,penggolongan pendapatan dapat dipisahkan dalam tiga
kategori, yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
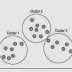
e. Pengklasteran (Clusterring)
Pengklasteran merupakan pengelompokan
record, pengamatan, atau
memperhatikan dan membentuk kelas obyek-obyek yang memiliki kemiripan. Klaster
adalah kumpulan record yang memiliki
kemiripan satu dengan yang lainnya dan memiliki ketidakmiripan
record dalam klaster
yang lain.Berbeda dengan klasifikasi, padapeng klasteran
tidak ada variabel target. Pengklasteran tidak melakukanklasifikasi,
mengestimasi, atau memprediksi nilai dari variabel target, akan tetapi,
algoritma pengklasteran mencoba untuk melakukan pembagian terhadap keseluruhan
data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan
record dalam
satu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam
kelompok lain akan bernilai minimal.
f. Asosiasi
Tugas asosiasi dalam data mining adalah
untuk menemukan atribut yangmuncul dalam satu waktu. Salah satu implementasi
dari asosiasi adalah
market basket analysis atau analisis keranjang
belanja, sebagaimana yang
akan
dibahas dalam tesis ini.